SmartLock Design Reference
Introduction
The Machine Learning solution uses a combination of 2D and 3D information processing to identify a specific human who wishes to access a restricted area.
Architectural Schematic
The base architecture of the SmartLock is briefly described in following image:
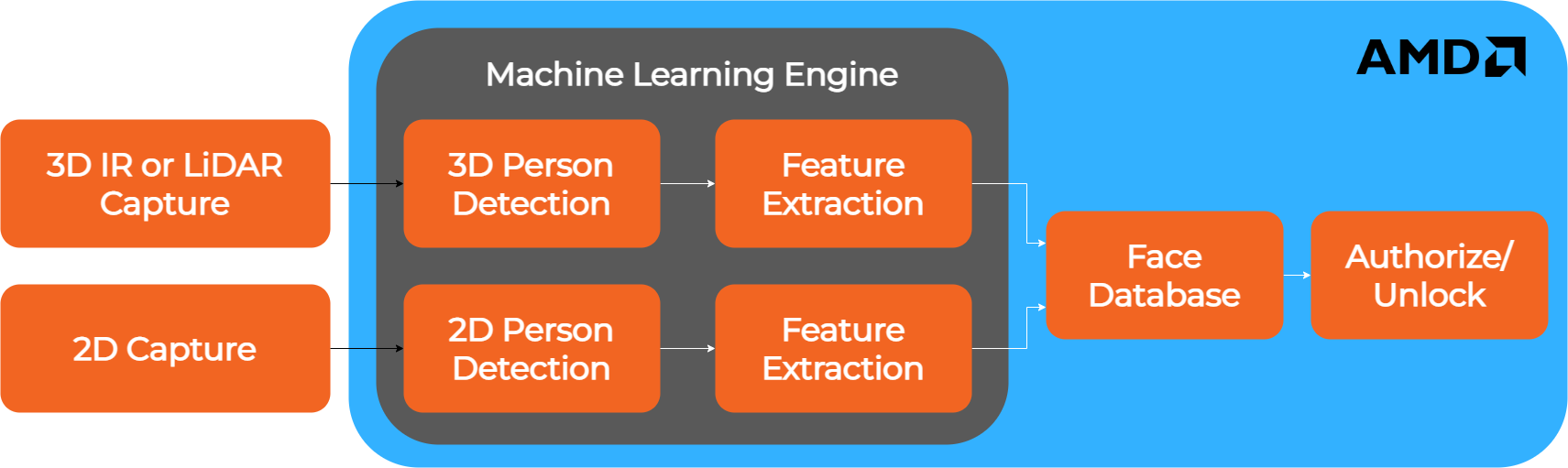
Fig. 1 - SmartLock Design Reference Architecture
The system is based on a Machine Learning engine which uses AI models to extract features from both the 2D and 3D acquisition data. Both branches (2D and 3D) have their own dedicated AI model for feature extraction. The extracted information is then fused together in order to compute the authorization process. Below is a brief description of the two branches.
2D Branch
This branch computes two different AI models in a cascade mode, first Face Detection and then Face Recognition. Face Detection is an AI model which analyzes an image from a video source. From this image are extracted, if present, the bounding boxes of the faces. The bounding boxes are a cropped version of the original image, containing only the faces, if present. Face Recognition is an AI model which receives the bounding box-cropped image of a face as input and returns a description of the face as output. The Face Recognition AI model is used to determine if the person in front of the SmartLock can be identified as someone who has been saved in the database as an authorized user.

|

|
|
Face Detection |
Face Recognition |
3D Branch
This branch is used to avoid efforts to spoof the 2D system. The function of this branch is to determine whether the 3D mapping of the person in front of the SmartLock is an human face. This rejects efforts to use images, photos, or other methods which can otherwise be accepted and recognized by the 2D system. This function is made building a point cloud of the real human face using the IR data coming from the onsemi AR0830CS sensor and a dot projector provided by ams OSRAM (ams OSRAM BELAGO1.1 VCSEL dot projector) which helps the IR 3D face reconstruction.

Fig. 2 - 3D data of a real face